Expedia, dünya çapında hizmet veren, oldukça büyük bir şirketler grubunun bir dalıdır. Bu şirket bir web sitesi üzerinden müşterilerine otel, uçak, gemi turları, araç kiralama gibi birçok rezervasyon hizmeti sunmaktadır. Müşteriler site üzerinden gitmek istedikleri ülkeyi, şehri, oteli arayarak, istedikleri tarihler arasında konaklamaya uygun olup olmadığını öğrenebilir ve isterlerse rezervasyon yaptırabilirler.
Arama için kullanılan kriterlerin istatistiki olarak incelenmesi ve çok sayıda olan bu verinin işlenmesi sayesinde, müşterilerin daha önceden yapmış olduğu benzer aramalara dayanarak, yeni bir müşterinin benzer aramalar sonucunda otel rezervasyonunu tamamlayıp tamamlamayacağı, hangi tür otellerde konaklamayı tercih ettiği gibi bilgiler üzerinde tahminler yürütülebilmektedir. Bu süreçte, kayıtlarda bulunan çok sayıda verinin çok katmanlı perceptron (MLP) yapısındaki yapay sinir ağları (YSA) veya destek vektör makineleri (SVM) gibi makine öğrenmesi teknikleri ile gerçeklenebilmektedir.
Bu çalışmada, Expedia tarafından sağlanan, 2013-2015 yılları arasında yapılmış arama verileri kullanılmıştır. Veri setinde bulunan 20 öznitelik ile oluşturulan yapay sinir ağı sistemleri ile müşterilerin yapmış olduğu arama sonucunda rezervasyon yapıp yapmayacağını tahmin eden bir sistem geliştirilmiştir.
KULLANILAN ÖZNİTELİKLER ve VERİ SETLERİ
Expedia, paylaşmış olduğu 7.5 milyon veri içerisinde müşteri hakkında ve yapmış olduğu arama hakkında çeşitli bilgiler sağlamaktadır. Sistemin eğitilmesi sırasında öznitelik olarak kullanılan bu bilgiler detaylı olarak Tablo 1’de açıklanmıştır.
Tablo 1 – Expedia tarafından sağlanan veri içerisinden kullanılan öznitelikler ve açıklaması
| Öznitelik | Açıklama |
| date_time | Arama Zamanı |
| site_name | Aramanın yapıldığı Expedia sitesi |
| posa_continent | Arama sitesinin bulunduğu kıta |
| user_loc_cntry | Müşterinin bulunduğu ülke |
| user_loc_region | Müşterinin bulunduğu bölge |
| user_loc_city | Müşterinin bulunduğu şehir |
| user_id | Müşteri numarası |
| is_mobile | Mobil cihaz kullanım durumu |
| is_package | Paket program durumu |
| channel | Pazarlama kanalı |
| srch_ci | Kayıt zamanı |
| srch_co | Çıkış zamanı |
| srch_adults_cnt | Yetişkin sayısı |
| srch_child_cnt | Çocuk sayısı |
| srch_rm_cnt | Otel odası sayısı |
| srch_dest_id | Aranan otel |
| srch_dest_type | Aranan otelin türü |
| hotel_continent | Aranan otelin kıtası |
| hotel_country | Aranan otelin ülkesi |
| hotel_market | Aranan otelin marketi |
| is_booking | Rezervasyon sonucu |
Bu çalışmada, sağlanan 7.5 milyonluk verinin içerisinden rastgele veriler seçilerek 100 binlik parçalar halinde veri setleri oluşturulmuştur. Bu veri setlerinden 1-5 arası olanlar eğitim için, genellikle 6. veri seti ise test için kullanılmıştır. Kullanılan yöntemler ve verilerin nasıl kullanıldığı sonraki bölümlerde detaylandırılmıştır.
İZLENEN MAKİNE ÖĞRENMESİ ADIMLARI ve SONUÇLARI
Bu çalışmada yapay sinir ağı modeli olarak tek gizli katmanı olan MLP yapısında ve SVM modelleri kullanılmıştır. Kullanılan MLP modeli farklı parametrelere göre incelenmiş, bu işlemler sırasında eğitim için kullanılan verinin %70’i ile sistem eğitilip, %15’i ile çapraz doğrulama yapılıp, kalan %15’u ile test edilmiştir. Oluşturulan modelin başarımı yeterli görüldüğü takdirde, eğitim setinden tamamen farklı olan bir veri seti kullanılarak sistemin tekrar testleri yapılmış ve gerçek başarımı ölçülmüştür. Müşterinin rezervasyon yapma durumu “1” sınıfı, yapmama durumu ise “0” sınıfı olarak adlandırılmıştır. Bu çalışmada kullanılan MLP ağının yapısı temsili gösterimi Şekil 1’deki gibidir.
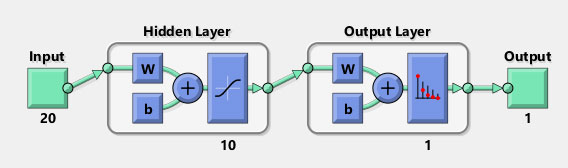
Şekil 1 – MLP ağı katman yapısının temsili gösterimi.
Bu yapıdaki bir MLP sisteminde parametre olarak sistemin gizli katman seviyesinde bulunan nöron sayısı parametre olarak değiştirilebilir bir yapıdadır. Örneğin 40 nöron kullanılarak yapılan bir eğitim ve test sonuçlarına ait başarım matrisleri sırasıyla Şekil 2 ve Şekil 3’de verilmiştir.
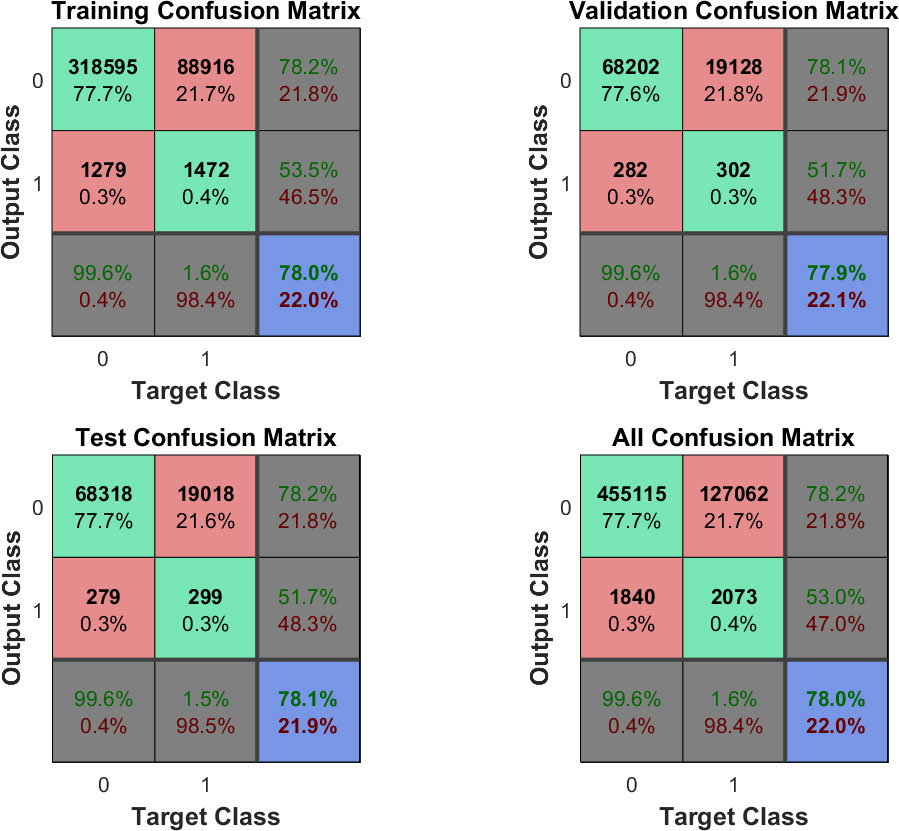
Şekil 2 – 40 nöron kullanan bir MLP ağının eğitim verisi üzerindeki başarım matrisi.
Burada yeşil renk ile gösterilen kısımlar doğru tahminleri, kırmızı ile gösterilen kısımlar ise yanlış tahminleri göstermektedir. Accuracy olarak adlandırılan, mavi alandaki yüzde değerleri sistemin genel başarım veya hata oranlarını içermektedir. 3. satırda bulunan gri renkli hücreler ise, Recall olarak adlandırılan, sistemin bir sınıf için yapmış olduğu tahminlerin o sınıf içerisindeki tüm veriye göre başarısının oranını göstermektedir. 3. sütundaki gri renkli hücreler ise, Presicion olarak adlandırılan, sistemin yapmış olduğu tahminlerin, o sınıfa ait tüm tahminlere oranını göstermektedir.
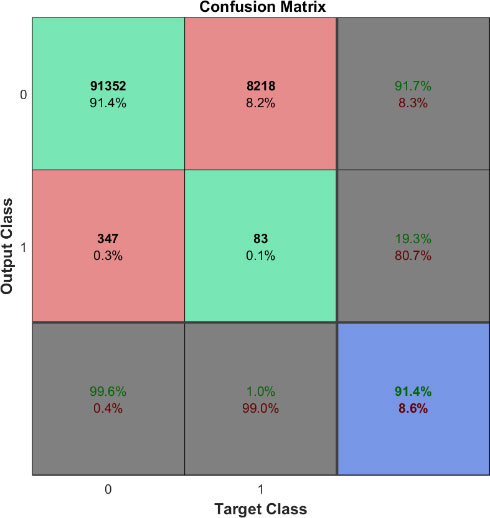
Şekil 3 – 40 nöron kullanan bir MLP ağının test verisi üzerindeki başarım matrisi.
Şekil 3’te gösterilen test verisi sonuçları başarım matrisi incelendiğinde, sistemin her ne kadar %91.4 başarılı olduğu gözlense de, verilerin çoğunun “0” sınıfına ait olduğu görülmektedir. “1” sınıfına ait verilerin %99’u hatalı olarak sınıflandırılmıştır. Bu sonuç aslında istenen bir sonuç değildir ve veri içerisinde bulunan sınıfların dağılımının eşitsizliği nedeniyle kaynaklanmaktadır. Bu soruna “class imbalance problem” ismi verilmektedir. Bu problemin çözümü için “1” sınıfına ait verilerin tekrar edilmesi, sistemin daha kararlı bir yapıya sahip olması için faydalı olmaktadır. Verinin tekrar edilmesi sonucu elde edilen sistemlerin başarım oranları eğitim ve test verisi için sırasıyla Tablo 2 ve Tablo 3’de verilmiştir.
Tablo 2 – Tekrarlanan verilerin eğitim verisi sonucuna göre sistem başarımına etkisi
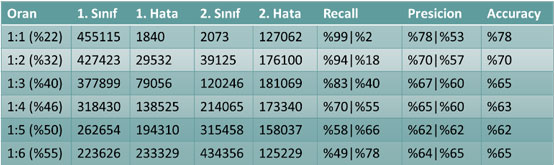
Tablo 3 – Tekrarlanan verilerin test verisi sonucuna göre sistem başarımına etkisi
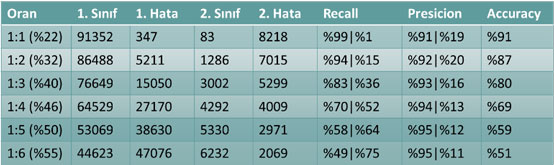
Burada, örneğin 1:2, 1. sınıfın olduğu gibi, 2. sınıfın iki kez tekrarlanarak eklendiğini göstermektedir. %32 ise, 2. sınıfa ait verinin, toplam verinin %32’sine karşılık geldiğini göstermektedir. Sonuçlara dikkat edilirse sistemin genel başarısı düşmekte fakat sınıflar içerisindeki başarım oranları toplamı artmaktadır. Sistem başarısının en makul ve istenen sonucu “1:5” oranında verdiği gözlenmiştir.
Verideki “class imbalance” probleminin dışında, sistemin gizli katmanında kullanılan nöron sayısının da sistem başarısına etkisi incelenmiştir. Bu incelemenin etkileri test verisi sonuçları üzerinden Tablo 4’de değerlendirilmiştir.
Tablo 4 – Gizli katman nöron verilerin test verisi sonucuna göre sistem başarımına etkisi

Bu problem için nöron sayısının başarıma doğrudan bir etkisi olmasa da, düşük sayıda nöron kullanılmasının bir miktar daha başarılı olduğu gözlenmiştir.
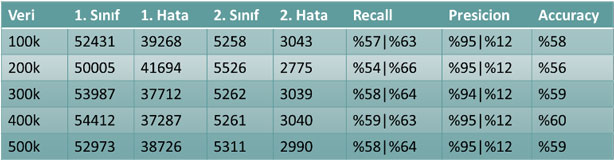
Bu etkenlerin dışında, eğitim için kullanılan veri miktarının büyüklüğü de sistemin başarımını etkileyebilmektedir. Eğitim veri setindeki veri miktarının, sistemin test verisi üzerindeki başarımına etkisi Tablo 5’de gösterilmiştir.
Tablo 5 – Eğitim verisi miktarının test verisi sonucuna göre sistem başarımına etkisi
Ayrıca veri setinden bazı özniteliklerin çıkarılmasının da test sonucuna etkisi olması beklenmektedir. Bu bağlamda bazı öznitelikler veri setinden çıkarılarak iki farklı (D1, D2) alt veri kümesi oluşturulmuştur. D1 veri setinden “date_time”, “user_id”, “srch_ci” , “srch_co” ve “srch_dest_id” verileri çıkarılırken, D2 setinden “user_loc_city”, “srch_ci” , “srch_co”, “srch_dest_id”, “hotel_contitent” ve “hotel_market” verileri çıkarılmıştır. Bu verilerin sisteme eğitim verisi olarak kullanılması ile elde edilen sonuçlar ise Tablo 6’da verilmiştir.
Tablo 6 – Farklı eğitim verisi kullanımının test verisi sonucuna göre sistem başarımına etkisi
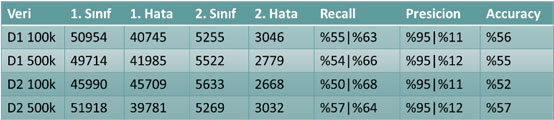
Yapılan incelemeler sonucunda başarılı sonuçlar veren 40-nöron, 500bin veri ve %50 sınıf dengesi durumunun başarılı sonuçlar sağladığı görülmüştür. Bu sınıfın başarımının denenmesi amacıyla iki farklı sistem oluşturulmuş ve sistemlerin başarımları Tablo 7’de verilmiştir. İkinci sistemin sonuçları “v2” soneki ile belirtilmiştir.
Tablo 7 – 40-nöron, 500bin veri ve %50 sınıf dengesi ile oluşturulan MLP sistemlerinin farklı test setleri üzerinde başarım sonuçları
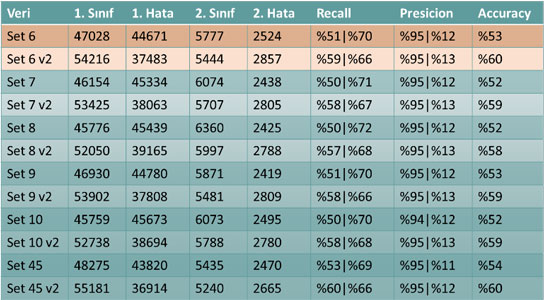
Problem ayrıca makine öğrenme sistemlerinden olan SVM yapısı kullanılarak modellenmiş ve elde edilen test sonuçları Tablo 8’de verilmiştir.
Tablo 8 – SVM sistemi test sonuçları
SONUÇLAR
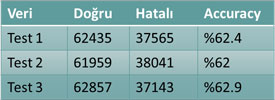
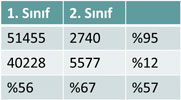
Bu çalışmada, Expedia web sitesinin sağlamış olduğu veriler kullanılarak eğitilen MLP ve SVM yapısındaki YSA sistemlerinin başarımı incelenmiştir. Bu süreçte, nöron sayısı, veri sayısı, sınıf veri dengesi gibi parametrelerin etkileri incelenmiştir. Sonuç olarak en başarılı tespitlerin daha çok sayıda veri kullanılarak, sınıf dengesinin %50’ye yakın olduğu YSA’ların daha başarılı olduğu görülmüştür. Başarım oranı en yüksek olan sistemlerden biri seçilerek eğitim verisinden tamamen bağımsız olan test veri setinde yapılan denemelerde “%62-63” oranında doğru tahmin yapılmıştır. Veri setlerinin başarım oranları Tablo 9’da detaylandırılmıştır.
Tablo 9 – Elde edilen en iyi sistemin test verisi üzerindeki başarımı